End-to-end dapper tutorial¶
This notebook walks through a minimal end-to-end dapper workflow for three 0.5° × 0.5° grid cells. It highlights the core functionality of dapper but does not get into details. Other notebooks do deeper dives into elements of dapper functionality.
dapper supports two run modes:
mode="sites": one set of ELM files per geometry (per grid cell in our case here, orgidindapperterminology).mode="cellset": one set of ELM files total containing multiple grid cells.
This notebook uses mode="sites", but the workflow remains the same if you want to use mode="cellset".
Important: “sites” does not mean at-a-point. Your input geometries can be polygons (as we do here).
When a point is needed (e.g., nearest-neighbor sampling or to label a cell), dapper computes and uses a representative point inside each polygon.
We also demonstrate the difference between point vs zonal sampling for surface and landuse file generation:
point/nearest: sample the underlying global file usingthe polygon’s representative point (nearest neighbor)
zonal: sample the underlying global file using the area-weighted intersection of the polygon with the source grid (spatial aggregation)
What you need locally to run this notebook.¶
Nothing that isn’t already in the repo! However, there are some steps for which you may want to use your data instead of the notebook’s.
For MET sampling, we include GEE sampling code that creates the raw CSV shards, but you can skip it and instead place pre-sampled CSVs in raw_gee_csvs/. Example data has already been placed here, so you do not need GEE access to run this notebook unless you want to sample the ERA5 met data on your own.
dapper cannot ship the global surface and landuse files (too big). However, a version of these is provided that has been cropped to a region that allows this notebook to run. If you have your own global surface and/or landuse files, you can point to them at the appropriate place in the notebook (or your own run script, eventually).
from pathlib import Path
# A helper function to make sure we're pathing correctly
def find_repo_root(start=None, markers=("pyproject.toml", "setup.cfg", ".git")) -> Path:
"""Walk upward from start (default: cwd) until a repo marker is found."""
p = Path(start or Path.cwd()).resolve()
for parent in (p, *p.parents):
if any((parent / m).exists() for m in markers):
return parent
raise FileNotFoundError(
"Could not find dapper repo root. Set manually."
)
# Locate the dapper repo - change if necessary
DAPPER_ROOT = find_repo_root() # this variable needs to be the dapper repo root directory; if you're not running this notebook from the notebook directory, you'll need to manually specify this
# Where to store outputs - feel free to change these paths
OUT_ROOT = DAPPER_ROOT / 'docs' / 'tutorials' / 'end-to-end' / 'outputs'
OUT_ROOT.mkdir(parents=True, exist_ok=True)
OUT_SITES = OUT_ROOT / "sites_mode" # just to differentiate between 'sites' and 'cellset' mode, although we won't be running 'cellset' here
# Where the (pre-sampled) GEE CSV shards live.
GEE_MET_SHARDS = Path(DAPPER_ROOT / "docs" / "data" / "end-to-end" / "gee_shards").resolve()
GEE_MET_SHARDS.mkdir(parents=True, exist_ok=True)
# In order to create surface and landuse files, we sample from global files. dapper provides these
# "pseudo-global" files that have been cropped from true global files to cover the areas of interest
# in this notebook. The actual global files are way too big for a GitHub repo. If you have access
# to global files (you should), you can use those paths here instead of these.
SURF_GLOBAL_NC = DAPPER_ROOT / 'docs' / 'data' / 'end-to-end' / 'surf_pseudoglobal.nc'
LANDUSE_GLOBAL_NC = DAPPER_ROOT / 'docs' / 'data' / 'end-to-end' / 'landuse_pseudoglobal.nc'
print("DAPPER_ROOT:", DAPPER_ROOT)
print("OUT_ROOT:", OUT_ROOT)
print("GEE_MET_SHARDS:", GEE_MET_SHARDS)
print("SURF_GLOBAL_NC:", SURF_GLOBAL_NC)
print("LANDUSE_GLOBAL_NC:", LANDUSE_GLOBAL_NC)
DAPPER_ROOT: X:\Research\NGEE Arctic\dapper
OUT_ROOT: X:\Research\NGEE Arctic\dapper\docs\tutorials\end-to-end\outputs
GEE_MET_SHARDS: X:\Research\NGEE Arctic\dapper\docs\data\end-to-end\gee_shards
SURF_GLOBAL_NC: X:\Research\NGEE Arctic\dapper\docs\data\end-to-end\surf_pseudoglobal.nc
LANDUSE_GLOBAL_NC: X:\Research\NGEE Arctic\dapper\docs\data\end-to-end\landuse_pseudoglobal.nc
Make our geometries¶
For this example, we’re just going to create three 0.5 degree grid cells centered in the Colville River Basin. You can obviously swap your own geometries in here (shapefile, geopackage, geojson, etc.).
We use shared latitude bounds:
lat: 69.25 → 69.75 (center 69.5)
Three adjacent longitude bounds (0.5° each):
cell_01: [-152.25, -151.75]
cell_02: [-151.75, -151.25]
cell_03: [-151.25, -150.75]
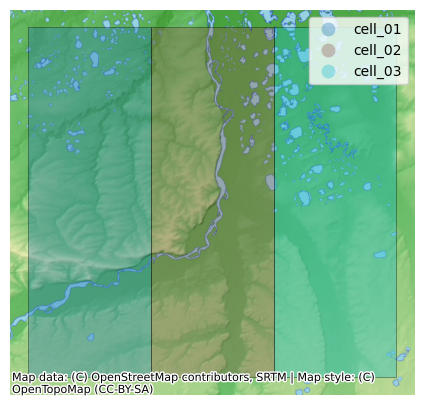
Let’s plot these cells on a basemap as a quick sanity check.
from shapely.geometry import box
import geopandas as gpd
from requests.exceptions import SSLError
lat_min, lat_max = 69.25, 69.75
lon_edges = [-152.25, -151.75, -151.25, -150.75] # 3 cells
rows = []
for i in range(3):
gid = f"cell_{i+1:02d}"
lon_min, lon_max = lon_edges[i], lon_edges[i+1]
geom = box(lon_min, lat_min, lon_max, lat_max)
rows.append({"gid": gid, "geometry": geom})
gdf_cells = gpd.GeoDataFrame(rows, crs="EPSG:4326")
gdf_cells
| gid | geometry | |
|---|---|---|
| 0 | cell_01 | POLYGON ((-151.75 69.25, -151.75 69.75, -152.2... |
| 1 | cell_02 | POLYGON ((-151.25 69.25, -151.25 69.75, -151.7... |
| 2 | cell_03 | POLYGON ((-150.75 69.25, -150.75 69.75, -151.2... |
# Plot the 3 cells on a basemap (uses dapper's topounit plotting helpers).
# If `contextily` isn't installed, we fall back to a simple boundary plot.
# If you get a connection error, disable your VPN.
try:
from dapper.topounit.topoplot import plot_static
gdf_plot = gdf_cells.copy()
gdf_plot["legend_label"] = gdf_plot["gid"] # plot_static colors by `legend_label`
plot_static(gdf_plot, basemap="terrain", figsize=(7, 5), alpha=0.35, legend=True)
except (ImportError, SSLError):
ax = gdf_cells.boundary.plot(figsize=(6, 4))
gdf_cells.apply(lambda r: ax.text(r.geometry.representative_point().x,
r.geometry.representative_point().y,
r["gid"]),
axis=1)
ax.set_title("Three 0.5° × 0.5° cells (no basemap)")
Create Domain Class¶
Any work you do using dapper requires that you are explicit about your geographical area(s) of focus. You can be focused on a site (point), a site (polygon/watershed), or many sites/grid cells. All of dapper’s functionality requires that you instantiate a Domain class. It’s easy to do.
Domain serves a couple of functions. One, it ensures that your specified area(s) of interest is/are formatted correctly and parseable. Two, it serves as a convenient way to access all of dapper’s functionality! No need to import individual functions–you can just use the methods contained in Domain.
Before we go on, I want to re-emphasize that this is a dapper design choice–everything starts with a user specifying the area(s) of interest.
The other thing that you need to decide at this point is if you want exports that are sites (each geometry you provide results in a set of input files) or cellset (all geometries will be in a single set of files). For this notebook, we’re just going to specify method=sites, but you can run it again with method=cellset if you’re unclear about what the difference is. If you do that, make sure to delete your old output files so you’re not confused.
One final note–the geometry(ies) you provide (as a GeoDataFrame, usually) must have a gid column with unique values. This column is used to name and keep track of your geometries. In our case, we’ve set gid to be ["cell_01", "cell_02", "cell_03"]. gid will get converted to a string if you use numeric values.
from dapper import Domain
# Keep polygons in Domain.cells for BOTH modes
domain = Domain.from_provided(
gdf_cells,
name="three_cells",
mode="sites",
cell_kind="as_provided",
) # OMG so easy
Met Data¶
This section has two parts:
(Optional) GEE sampling code that submits export tasks to Google Drive (creates the CSV shards that
dapperwill make ELM-ready).Exporting Met data from
RAW_GEE_CSVS_DIRinto ELM NetCDFs. I have already done the sampling and uploaded the shards to thedapperrepo, so you can skip step 1 if you want.
Here we will sample and export ERA5-Land hourly data for our 3 cells. There are many options we won’t be covering here (e.g. you can export at different time aggregations, there is an Adapter for FluxNet/Flux Tower data, etc.)
1) (Optional) GEE Sampling ERA5-Land¶
You will need to have installed earthengine-api (it’s a dapper dependency so you should already have it) and run ee.Authenticate() at least once.
This will create CSV shards in your specified Google Drive folder. After tasks complete, download them into RAW_GEE_CSVS_DIR.
You must set:
GEE_PROJECTGDRIVE_FOLDER
You can also set skip_tasks=True when calling sample_e5lh to do a dry-run validation without starting tasks. The code below has this set to False because I already ran this and exported the files; change it to True if you want to sample for yourself. Note that it will take some minutes (depends on GEE’s load).
GEE_PROJECT = 'ee-jonschwenk' # <-- must change me
GDRIVE_FOLDER = "dapper_e2e_3cells" # <-- change me if ya want
# Small time range for an example (adjust as desired)
START_DATE = "2020-01-01" # earliest available is 1950-01-01 (YYYY-MM-DD)
END_DATE = "2022-01-01" # keep small for a demo - can put 2100-01-01 to get the latest available data
import ee
from dapper import sample_e5lh
ee.Initialize(project=GEE_PROJECT)
sampling_params = dict(
start_date=START_DATE,
end_date=END_DATE,
geometries=domain, # can also pass domain_sites; geometries are the same here
geometry_id_field="gid",
gee_bands="elm", # "elm" or "all" or explicit list
gdrive_folder=GDRIVE_FOLDER,
job_name="e2e_3cells_era5",
gee_scale="native",
gee_years_per_task=1,
)
# Starts export tasks unless skip_tasks=True
dom_sample = sample_e5lh(sampling_params, skip_tasks=True) # change skip_tasks to False in order to actually start the tasks on GEE
2) Export to ELM-ready¶
GEE_MET_SHARDS should contain one or more *.csv shards with a gid column matching cell_01, cell_02, cell_03. A “shard” is just a *.csv file exported using the sample_e5lh function above.
If you have Fluxnet data, you can swap in FluxnetAdapter instead of ERA5Adapter—the export call is the same, only the adapter/config changes.
from dapper import ERA5Adapter
# Just a little check to make sure your CSV shards are available
def _has_csv_shards(p: Path) -> bool:
return any(p.glob("*.csv"))
print("CSV shards present:", _has_csv_shards(GEE_MET_SHARDS)) # If this is False, you need to fix something!
print(GEE_MET_SHARDS)
adapter = ERA5Adapter()
CSV shards present: True
X:\Research\NGEE Arctic\dapper\docs\data\end-to-end\gee_shards
# Export MET for sites mode (one MET directory per gid)
# Output: OUT_SITES/<gid>/MET/*.nc
met_sites = domain.export_met(
src_path=GEE_MET_SHARDS,
adapter=adapter,
out_dir=OUT_SITES,
calendar="noleap", # excludes Feb. 29
dtime_resolution_hrs=1, # can change if you want. I think even 0.5 works if you want interpolated 30-minute data, but I wouldn't recommend it.
dformat="BYPASS", # don't change this as no other options are supported. Eventually we might support DATM if needed.
overwrite=False,
append_attrs={"dapper_example": "hi mom!"}, # you can add metadata to the exported met netCDFs
)
met_sites
Processing file 1 of 2: X:\Research\NGEE Arctic\dapper\docs\data\end-to-end\gee_shards\e2e_3cells_era5_2020-01-01_2021-01-01.csv
Processing file 2 of 2: X:\Research\NGEE Arctic\dapper\docs\data\end-to-end\gee_shards\e2e_3cells_era5_2021-01-01_2022-01-01.csv
sites export complete.
{'cell_01': WindowsPath('X:/Research/NGEE Arctic/dapper/docs/tutorials/end-to-end/outputs/sites_mode/cell_01/MET'),
'cell_02': WindowsPath('X:/Research/NGEE Arctic/dapper/docs/tutorials/end-to-end/outputs/sites_mode/cell_02/MET'),
'cell_03': WindowsPath('X:/Research/NGEE Arctic/dapper/docs/tutorials/end-to-end/outputs/sites_mode/cell_03/MET')}
Domain file export¶
ELM typically expects a domain.nc describing the land mask / cell layout. We can export it for each cell easily.
domain.export_domain(out_dir=OUT_SITES, overwrite=True)
{'cell_01': WindowsPath('X:/Research/NGEE Arctic/dapper/docs/tutorials/end-to-end/outputs/sites_mode/cell_01/domain.nc'),
'cell_02': WindowsPath('X:/Research/NGEE Arctic/dapper/docs/tutorials/end-to-end/outputs/sites_mode/cell_02/domain.nc'),
'cell_03': WindowsPath('X:/Research/NGEE Arctic/dapper/docs/tutorials/end-to-end/outputs/sites_mode/cell_03/domain.nc')}
Surface + Landuse export (requires local global NetCDFs)¶
In addition to showing how surface and landuse files can be generated with dapper, this section also demonstrates point vs zonal sampling. dapper generates surface and landuse files from existing global ones. If your geometries are polygons, we can sample from these global files one of two ways:
nearest (point): sample at polygon representative point (nearest neighbor)
zonal: area-weighted intersection of polygon with the source grid (weighted-by-area spatial aggregation over your polygon)
You must make sure that the following two files exist (pseudo-global versions are shipped with dapper and should already be locked in for this notebook):
SURF_GLOBAL_NC(surface global)LANDUSE_GLOBAL_NC(landuse global)
You can also subset variables (or rename variables) during export; this notebook sticks to defaults for clarity.
Surface files export (nearest-neighbor sampling)¶
One thing we’ll bring attention to in this block is that you can include the append_attrs keyword and provide a dict that has key:value pairs of any extra metadata you want to append to your exported files. This works for all the export_XXX() methods. dapper also automatically appends some metadata to exported .nc files that helps track provenance and methods used to generate it.
import xarray as xr
surf_sites = domain.export_surface(
src_path=SURF_GLOBAL_NC,
out_dir=OUT_SITES,
filename="surfdata.nc",
overwrite=False,
sampling_method="nearest",
append_attrs={"dapper_example": "hi mom!", "sampling": "nearest"},
)
print("sites surface:", surf_sites)
sites surface: {'cell_01': WindowsPath('X:/Research/NGEE Arctic/dapper/docs/tutorials/end-to-end/outputs/sites_mode/cell_01/surfdata.nc'), 'cell_02': WindowsPath('X:/Research/NGEE Arctic/dapper/docs/tutorials/end-to-end/outputs/sites_mode/cell_02/surfdata.nc'), 'cell_03': WindowsPath('X:/Research/NGEE Arctic/dapper/docs/tutorials/end-to-end/outputs/sites_mode/cell_03/surfdata.nc')}
Landuse files export (zonal sampling)¶
Here we follow the same pattern as the surface files export, except we’ll use sampling_method=zonal. From a user perspective, it’s a small change, but it can make a big difference in the resulting sampled values.
landuse_zonal = domain.export_landuse(
src_path=LANDUSE_GLOBAL_NC,
out_dir=OUT_SITES,
filename="landuse_zonal.nc",
overwrite=False,
sampling_method="zonal",
append_attrs={"dapper_example": "e2e_3cells_cellset", "sampling": "zonal"},
)
Summary: what got written?¶
Take a look at our OUT_SITES directory. The following code block with print the OUT_ROOT directory tree so we can look at the files (you can also just look at them via your OS browser).
def tree(p):
p = Path(p)
print(p.name + "/")
for x in sorted(p.rglob("*"), key=lambda x: (x.parts, x.is_file(), x.name)):
depth = len(x.relative_to(p).parts) - 1
print(" " * depth + ("└─ " if x.is_file() else "├─ ") + x.name + ("/" if x.is_dir() else ""))
tree(OUT_ROOT)
outputs/
├─ sites_mode/
├─ cell_01/
├─ MET/
└─ FLDS.nc
└─ FSDS.nc
└─ PRECTmms.nc
└─ PSRF.nc
└─ QBOT.nc
└─ TBOT.nc
└─ WIND.nc
└─ zone_mappings.txt
└─ domain.nc
└─ landuse_zonal.nc
└─ landuse_zonal.nc.zonal_weights.csv
└─ surfdata.nc
├─ cell_02/
├─ MET/
└─ FLDS.nc
└─ FSDS.nc
└─ PRECTmms.nc
└─ PSRF.nc
└─ QBOT.nc
└─ TBOT.nc
└─ WIND.nc
└─ zone_mappings.txt
└─ domain.nc
└─ landuse_zonal.nc
└─ landuse_zonal.nc.zonal_weights.csv
└─ surfdata.nc
├─ cell_03/
├─ MET/
└─ FLDS.nc
└─ FSDS.nc
└─ PRECTmms.nc
└─ PSRF.nc
└─ QBOT.nc
└─ TBOT.nc
└─ WIND.nc
└─ zone_mappings.txt
└─ domain.nc
└─ landuse_zonal.nc
└─ landuse_zonal.nc.zonal_weights.csv
└─ surfdata.nc
The first thing to point out is that we have 3 sets of output folders (cell01, cell_02, and cell_03). Each of those has a complete set of ELM-ready files. This is because we selected method=sites when we insantiated the Domain class. We could re-run this notebook exactly the same, but set method=cellset, and the result at the end would be one set of files, where each file contains all three cells. Try it out!
If we dig in a little futher, we see that a MET directory is created for each site. That MET directory contains 8 meteorological variables sampled from ERA5-Land hourly. It also contains a zone_mappings.txt file needed to run ELM.
We also see the domain.nc, landuse.nc, and surfdata.nc files needed to run ELM. Again, here we have 3 sets of these (one per site), but we could put all this data into single files if we used method=cellset. You also see a XXX.zonal_weights.csv. When we sample surface and/or landuse files with sampling_method=zonal, this file simply contains the weights that were used to spatially aggregate each parameter.
Here is a good place to put a couple disclaimers:
dappercurrently only has very basic functionality to validate that the values in the output files are correct. You should check the values in each file to make sure they’re what you expect.Using
sampling_method=zonalshould be considered somewhat beta. This is because: every parameter in the global file (and there are dozens) requires the correct spatial aggregation method.dappercurrently employs a fairly basic method to determine how to perform this aggregation (based on datatype), but these methods should eventually be defined explicitly for every parameter. As an example of what I mean here: if a parameter is a “class” variable (1=landtype1,2=landtype2, etc.), then spatial aggregation should be done bymode, notaverage.
Quick check of written files¶
We won’t go in depth here on exploring the dapper outputs (see the other notebooks for that), but let’s just open a single file and look at the variables it contains and its metadata.
INSPECT_PATH = OUT_SITES / 'cell_01' / 'surfdata.nc'
# Let's look at the dimensions
ds = xr.open_dataset(INSPECT_PATH, decode_cf=False)
print("Dimensions:")
for dim, n in ds.sizes.items():
print(f" {dim}: {n}")
Dimensions:
lsmlat: 1
lsmlon: 1
nlevsoi: 10
natpft: 17
time: 12
lsmpft: 17
nlevslp: 11
numurbl: 3
numrad: 2
nlevurb: 5
nglcec: 10
nglcecp1: 11
# Let's look at all the parameters in our file
vars_flat = ", ".join(sorted(ds.variables.keys()))
print(vars_flat)
ALB_IMPROAD_DIF, ALB_IMPROAD_DIR, ALB_PERROAD_DIF, ALB_PERROAD_DIR, ALB_ROOF_DIF, ALB_ROOF_DIR, ALB_WALL_DIF, ALB_WALL_DIR, APATITE_P, AREA, CANYON_HWR, CV_IMPROAD, CV_ROOF, CV_WALL, Ds, Dsmax, EF1_BTR, EF1_CRP, EF1_FDT, EF1_FET, EF1_GRS, EF1_SHR, EM_IMPROAD, EM_PERROAD, EM_ROOF, EM_WALL, F0, FMAX, GLC_MEC, HT_ROOF, LABILE_P, LAKEDEPTH, LANDFRAC_PFT, LATIXY, LONGXY, MONTHLY_HEIGHT_BOT, MONTHLY_HEIGHT_TOP, MONTHLY_LAI, MONTHLY_SAI, NLEV_IMPROAD, OCCLUDED_P, ORGANIC, P3, PCT_CLAY, PCT_CROP, PCT_GLACIER, PCT_GLC_GIC, PCT_GLC_ICESHEET, PCT_GLC_MEC, PCT_GLC_MEC_GIC, PCT_GLC_MEC_ICESHEET, PCT_GRVL, PCT_LAKE, PCT_NATVEG, PCT_NAT_PFT, PCT_SAND, PCT_URBAN, PCT_WETLAND, PFTDATA_MASK, SECONDARY_P, SINSL_COSAS, SINSL_SINAS, SKY_VIEW, SLOPE, SLP_P10, SOIL_COLOR, SOIL_ORDER, STDEV_ELEV, STD_ELEV, TERRAIN_CONFIG, THICK_ROOF, THICK_WALL, TK_IMPROAD, TK_ROOF, TK_WALL, TOPO, TOPO_GLC_MEC, T_BUILDING_MAX, T_BUILDING_MIN, URBAN_REGION_ID, WIND_HGT_CANYON, WTLUNIT_ROOF, WTROAD_PERV, Ws, ZWT0, abm, binfl, gdp, mxsoil_color, mxsoil_order, natpft, parEro_c1, parEro_c2, parEro_c3, peatf, time
# And finally let's look at the metadata
if ds.attrs:
for k, v in ds.attrs.items():
print(f"{k}: {v}")
else:
print("(no global attrs)")
Conventions: NCAR-CSM
History_Log: created on: 06-09-20 11:44:04
Logname: gbisht
Host: cori10
Source: Community Land Model: CLM4
Version: $HeadURL: https://svn-ccsm-models.cgd.ucar.edu/clm2/trunk_tags/clm4_5_1_r085/models/lnd/clm/tools/clm4_5/mksurfdata_map/src/mkfileMod.F90 $
Revision_Id: $Id: mkfileMod.F90 47951 2013-06-12 11:13:58Z sacks $
Compiler_Optimized: TRUE
no_inlandwet: TRUE
nglcec: 10
Input_grid_dataset: map_0.5x0.5_MODIS_to_0.5x0.5_nomask_aave_da_c190417.nc
Input_gridtype: global
VOC_EF_raw_data_file_name: mksrf_vocef_0.5x0.5_simyr2000.c110531.nc
Inland_lake_raw_data_file_name: mksrf_LakePnDepth_3x3min_simyr2004_c111116.nc
Inland_wetland_raw_data_file_name: mksrf_lanwat.050425.nc
Glacier_raw_data_file_name: mksrf_glacier_3x3min_simyr2000.c120926.nc
Urban_Topography_raw_data_file_name: mksrf_topo.10min.c080912.nc
Land_Topography_raw_data_file_name: topodata_10min_USGS_071205.nc
Urban_raw_data_file_name: mksrf_urban_0.05x0.05_simyr2000.c120621.nc
Lai_raw_data_file_name: mksrf_lai_global_c090506.nc
agfirepkmon_raw_data_file_name: mksrf_abm_0.5x0.5_AVHRR_simyr2000.c130201.nc
gdp_raw_data_file_name: mksrf_gdp_0.5x0.5_AVHRR_simyr2000.c130228.nc
peatland_raw_data_file_name: mksrf_peatf_0.5x0.5_AVHRR_simyr2000.c130228.nc
topography_stats_raw_data_file_name: mksrf_topostats_1km-merge-10min_HYDRO1K-merge-nomask_simyr2000.c130402.nc
vic_raw_data_file_name: mksrf_vic_0.9x1.25_GRDC_simyr2000.c130307.nc
ch4_params_raw_data_file_name: mksrf_ch4inversion_360x720_cruncep_simyr2000.c130322.nc
map_pft_file_name: map_0.5x0.5_MODIS_to_0.5x0.5_nomask_aave_da_c190417.nc
map_lakwat_file: map_3x3min_MODIS_to_0.5x0.5_nomask_aave_da_c190417.nc
map_wetlnd_file: map_0.5x0.5_AVHRR_to_0.5x0.5_nomask_aave_da_c190417.nc
map_glacier_file: map_3x3min_GLOBE-Gardner_to_0.5x0.5_nomask_aave_da_c190417.nc
map_soil_texture_file: map_5x5min_IGBP-GSDP_to_0.5x0.5_nomask_aave_da_c190417.nc
map_soil_color_file: map_0.5x0.5_MODIS_to_0.5x0.5_nomask_aave_da_c190417.nc
map_soil_order_file: map_0.5x0.5_MODIS_to_0.5x0.5_nomask_aave_da_c190417.nc
map_soil_organic_file: map_5x5min_ISRIC-WISE_to_0.5x0.5_nomask_aave_da_c190417.nc
map_urban_file: map_3x3min_LandScan2004_to_0.5x0.5_nomask_aave_da_c190417.nc
map_fmax_file: map_3x3min_USGS_to_0.5x0.5_nomask_aave_da_c190417.nc
map_VOC_EF_file: map_0.5x0.5_AVHRR_to_0.5x0.5_nomask_aave_da_c190417.nc
map_harvest_file: map_0.5x0.5_MODIS_to_0.5x0.5_nomask_aave_da_c190417.nc
map_lai_sai_file: map_0.5x0.5_MODIS_to_0.5x0.5_nomask_aave_da_c190417.nc
map_urban_topography_file: map_10x10min_nomask_to_0.5x0.5_nomask_aave_da_c190417.nc
map_land_topography_file: map_10x10min_nomask_to_0.5x0.5_nomask_aave_da_c190417.nc
map_agfirepkmon_file: map_0.5x0.5_AVHRR_to_0.5x0.5_nomask_aave_da_c190417.nc
map_gdp_file: map_0.5x0.5_AVHRR_to_0.5x0.5_nomask_aave_da_c190417.nc
map_peatland_file: map_0.5x0.5_AVHRR_to_0.5x0.5_nomask_aave_da_c190417.nc
map_topography_stats_file: map_1km-merge-10min_HYDRO1K-merge-nomask_to_0.5x0.5_nomask_aave_da_c190417.nc
map_vic_file: map_0.9x1.25_GRDC_to_0.5x0.5_nomask_aave_da_c190417.nc
map_ch4_params_file: map_360x720cru_cruncep_to_0.5x0.5_nomask_aave_da_c190417.nc
map_gravel_file: map_5x5min_ISRIC-WISE_to_0.5x0.5_nomask_aave_da_c190417.nc
map_slp10_file: map_0.5x0.5_AVHRR_to_0.5x0.5_nomask_aave_da_c190417.nc
map_erosion_file: map_0.5x0.5_AVHRR_to_0.5x0.5_nomask_aave_da_c190417.nc
Soil_texture_raw_data_file_name: mksrf_soitex.10level.c010119.nc
Soil_color_raw_data_file_name: mksrf_soilcol_global_c090324.nc
Soil_order_raw_data_file_name: mksrf_soilord_global_c150313.nc
Fmax_raw_data_file_name: mksrf_fmax_3x3min_USGS_c120911.nc
Organic_matter_raw_data_file_name: mksrf_organic_10level_5x5min_ISRIC-WISE-NCSCD_nlev7_c120830.nc
Vegetation_type_raw_data_filename: LUT_LUH2_historical_1850_04082019.nc
soil_gravel_raw_data_file_name: mksrf_gravel_10level_5min.c190603.nc
slope_percentile_raw_data_file_name: mksrf_slope_10p_0.5x0.5.c190603.nc
erosion_raw_data_file_name: mksrf_soilero_0.5x0.5.c190603.nc
dapper_example: hi mom!
sampling: nearest
dapper_created_utc: 2026-01-10T02:03:08.655328Z
The only thing I’ll point out here is that dapper copies all the metadata from the base global files. It also auto-appends the creation date, and we added a couple custom metadata keys. For example:
print(ds.attrs['dapper_example'])
hi mom!